![[JPA] JPA의 장점과 그 원리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdgHeTx%2FbtsA1bESCZr%2FKNYGQqMEAK1KkkRvvxfF5K%2Fimg.png)
이전 포스팅에서 객체지향프로그래밍과 데이터베이스간 패러다임 불일치로 발생하는 문제들을 알아봤다. 이번에는 JPA가 이런 문제를 어떻게 해결하는지 알아보자.
새로운 계층: JPA 레이어
JPA는 데이터베이스와 애플리케이션 사이에서 동작한다. 계층이 하나 더 있기 때문에 최적화 관점에서 시도해 볼 수 있는 것이 많다.

1. 지연 로딩
Customer를 조회할 때 Orders속성에 명시적으로 액세스할 때까지 SELECT 쿼리가 나가지 않는다.
@Entity
public class Customer {
@OneToMany(mappedBy = "customer")
private List<Order> orders;
}
2. Batch Fetching
관련 엔티티를 일괄적으로 로드하여 쿼리 수를 최소화한다.
@Entity
public class Customer {
@OneToMany(mappedBy = "customer", fetch = FetchType.LAZY)
@BatchSize(size = 10)
private List<Order> orders;
}
3. 캐싱
반복되는 데이터베이스 쿼리의 필요성을 줄이기 위해 자주 엑세스하는 데이터를 메모리에 저장할 수 있다. 특정 엔티티에 대한 캐싱은 @Cacheable을 사용할 수 있다.
@Entity
@Cacheable
public class Product {
// fields...
}
4. 트랜잭션 관리
트랜잭션의 옵션 값 readOnly = true로 설정함으로써 읽기 전용 쿼리로 만들 수 있다. 이를 통해 실수로 인한 데이터 저장, 수정을 막을 수 있고 분산환경에서 읽기 전용 데이터베이스만을 이용하도록 할 수 있다.
@Service
@Transactional(readonly = true)
public class CustomerService {
// @Transactional 을 붙이지 않으면 업데이트 되지 않는다.
public void updateCustomerDetails(Customer updatedCustomer) {
// ... update customer details ...
}
}
5. 데이터 접근 추상화
추상화를 통해 개발자는 데이터베이스 독립적인 코드를 작성할 수 있다. MySQL을 기준으로 개발을 진행해도 중간에 Oracle로 쉽게 바꿀 수 있다.
이런 기능을 제공할 수 있는 이유는 JPA가 있는 새로운 계층에서 영속성 컨텍스트라는 것을 이용하기 때문이다.
영속성 컨텍스트
영속성 컨텍스트란 엔티티를 영구 저장하는 환경을 말하며 다음과 같은 구조를 가지고 있다.

이런 영속성 컨텍스트를 이용하면 다음과 같은 장점을 가질 수 있다.
- 1차 캐시 : 영속성 컨텍스트 내부에는 캐시를 가지고 있으며 데이터를 영속화(persist())하면 데이터가 1차 캐시에 저장된다.
- 쓰기 지연 : 1차 캐시에 데이터가 저장되면 쓰기 지연 저장소에 SQL 쿼리를 만들어 저장했다가 트랜잭션이 커밋되는 시점에 데이터베이스에 동기화 한다. 이 기능을 활용하면 모아둔 쿼리를 데이터베이스에 한 번에 전달해서 성능을 최적화할 수 있다.
- 변경 감지 : SQL 중심의 개발을 하다보면 수 많은 업데이트 쿼리가 생기게 된다.
UPDATE CUSTOMER
SET
NAME=?
PHONE_NUMBER=?
WHERE
ID=?
UPDATE CUSTOMER
SET
NAME=?
WHERE
ID=?이렇게 SQL에 의존적인 개발을 해결하기 위해 JPA는 변경 감지 기능을 제공한다. 변경 감지의 동작 순서는 다음과 같다.
- JPA는 데이터를 영속화시킬 때 최초 상태를 복사하여 저장해둔다. 이를 스냅샷이라고 한다.
- 데이터베이스에 플러쉬할 때 최초 상태와 Entity 상태를 비교하여 UPDATE쿼리를 날린다.
퀴즈
영속성 컨텍스트를 이해하기 위해 다음 문제에 대한 답을 예측해보자.
1. 다음 코드에서 변경 감지가 동작할 지 예측해보자.
@PostMapping("/")
public Student saveStudent() {
Student student = studentService.save();
student.name = "changed";
return student;
}
public class StudentService {
public Student save() {
Student student = Student.builder()
.name("mango")
.grade("30")
.sn("1")
.build();
return studentRepository.save(student);
}
}다음에서는 변경 감지가 동작하지 않는다. 스프링에서 트랜잭션은 기본적으로 서비스-레포지토리까지만 유지되기 때문에 Controller에서 데이터를 변경해도 데이터베이스에는 적용되지 않는다.

2. 다음 코드는 잘 동작할까? 쿼리문은 어떻게 나갈지 예측해보자
public class StudnetController {
@PostMapping("/")
public Student saveStudent() {
return studentService.save();
}
}
public class StudentService {
public Student save() {
Student student = Student.builder()
.name("mango")
.grade("30")
.sn("1")
.build();
studentRepository.save(student);
student.name = "changed";
return student;
}
}INSERT와 UPDATE 쿼리가 한 번씩 나가게 된다.
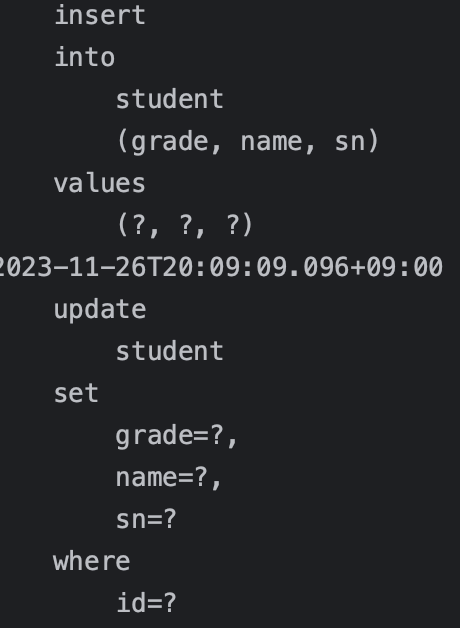
그런데 UPDATE 쿼리를 보면 조금 이상하다. name필드만 업데이트가 되어야 하는데 모든 필드에 대해서 업데이트하고 있다. 즉, JPA는 엔티티의 모든 필드를 업데이트한다. 이렇게 함으로써 데이터베이스에 보내는 전송량이 증가하는 단점이 있지만 다음과 같은 장점이 생긴다.
1. 수정 쿼리가 항상 같기 때문에 애플리케이션 로딩 시점에 수정 쿼리를 미리 생성해두고 재사용할 수 있다.
2. 데이터베이스에 동일한 쿼리를 보내면 데이터베이스는 이전에 한 번 파싱된 쿼리를 재사용할 수 있다.
- 쿼리를 처음 실행하면 JPA가 쿼리 구문을 분석하고 컴파일한다. 이 때, 컴파일된 표현은 JPA 공급자에 의해 캐시 된다.
마지막 문제로 다음 상황에서 쿼리를 예측해보자.
1. Student Entity를 저장한다.
2. 데이터베이스에 flush()한다.
3. findById를 이용해 studnet객체를 조회한다.
@Transactional
public Student save() {
Student student = Student.builder()
.name("mango")
.grade("30")
.sn("1")
.build();
studentRepository.save(student);
studentRepository.flush();
Student student1 = studentRepository.findById(student.getId()).orElseThrow();
System.out.println(student1);
return student;
}Flush는 동기화이지 데이터를 비우지 않는다. 따라서 조회 쿼리가 나가지 않고 영속성 컨텍스트의 1차 캐시에서 값을 가져온다.

JPA는 장점만 있을까? 단점도 알아보자.
JPA의 단점
1. 일괄 작업에는 적합하지 않다
객체 관계형 매핑 계층과 같이 JPA에서 제공하는 추가 추상화로 인한 오버헤드 때문에 대규모 배치 작업에서 성능이 중요하다면 JPA는 적합하지 않다.
2. 메모리 소비
엔티티 개체 및 해당 관계를 관리하는 특성으로 인해 JDBC에 비해 더 많은 메모리를 소비한다.
3. 러닝 커브
JPA를 이해하기 위해서는 SQL과 객체지향 프로그래밍 그리고 Hibernate에 대해서 이해해야 하기 때문에 러닝 커브가 크다.