![[운영체제] 스케줄링 알고리즘(2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FTBIrR%2Fbtq17HeVB8P%2FZooL2nGfibUMuh0SMvNTVK%2Fimg.png)
지난 포스팅의 선입 선처리 스케줄링과 최단 작업 우선스케줄링에 이어 나머지 스케줄링 알고리즘에 대하여 알아보려고 한다.
[라운드 로빈 스케줄링]
라운드 로빈 스케줄링에서 모든 프로세스들은 똑같은 cpu 작업 시간을 할당 받는다(Time Quantum)
n개의 프로세스, q의 작업 시간을 갖는다고 하면 각 프로세스는 1/n의 cpu 작업 시간을 할당 받고 (n-1)q 이상 기다리지 않는다.
이 경우에 만약 한 프로세스가 q시간에 작업을 끝내지 못내도 다음 프로세스로 전환된다. 여기서 발생할 수 있는 문제점은 만약 q가 문맥 교환시간보다 작다면 overhead가 너무 커져버린다.
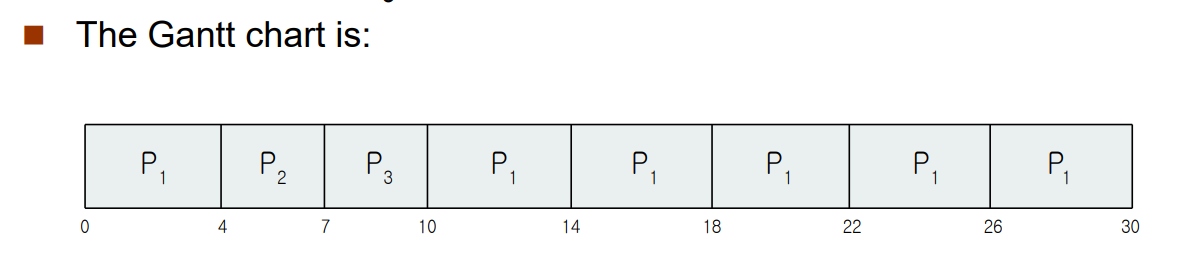
평균 대기 시간을 계산해보자. P1은 (10-4), P2는 4, P3는 7밀리초를 기다린다.
따라서 17 / 3 = 5.66 밀리초가 된다.
CPU작업시간이 클수록 문맥 교환시간이 줄어들기 때문에 효율적으로 보일 수 있는데
마냥 작업시간을 늘리게 되면 선입 선처리 정책으로 퇴보된다. 따라서 CPU버스트의 80%는 시간 할당량보다 짧아야 한다.
[우선순위 스케줄링]
낮은 숫자는 높은 우선순위를 가지고 있다고 가정한다.(정해진 약속이 없다)
우선순위 스케줄링은 말 그대로 우선순위가 높은 순서대로 처리하는 스케줄링 방법이다.
아래의 경우를 보자.
| 프로세스 | 버스트 시간 | 도착시간 |
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |
우선수위를 기준으로 다음과 같이 스케줄을 할 것이다.

평균 대기 시간은 8.2밀리초이다.
우선수위 스케줄링의 문제로는 기아 상태가 있다.
기아 상태 : 우선순위가 낮은 프로세스는 대기를 해야 하는데 만약 우선순위가 높은 프로세스가 계속 들어오게 되면 우선순위가 낮은 프로세스는 무한 대기 중인 상태가 된다.
이를 해결하기 위해 노화(Aging)을 이용한다. 노화는 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증사킨다.
또 다른 방법으로 라운드 로빈과 우선순위 스케줄링을 결합하는 방법이다. (p.235)
[다단계 큐 스케줄링]
우선순위와 라운드 로빈 스케줄링을 할 때 모든 프로세스가 단일 큐에 배치되고 스케줄러는 우선순위가 가장 높은 프로세스를 선택하여 실행시킬 수 있다. 이 때 우선순위가 가장 높은 프로세스를 결정하기 위해 O(n) 검색이 필요할 수 있는데, 이 때 우선순위마다 별도의 큐를 갖는 것이 더 쉬울 때가 있다.
다단계 큐에서는 프로세스 유형에 따라 프로세스를 여러 개의 큐로 분할한다.
흔히 포그라운드(대화형)프로세스와 백그라운드(배치) 프로세스를 구분한다.
각각의 큐는 자신만의 스케줄링 알고리즘을 가질 수 있으며 스케줄링은 큐들 사이에서도 존재해야 한다.
이 때 주로 사용되는 방법이 2가지가 있는데
1 ) Fixed priority scheduling : 우선순위를 고정하고 실행하는 방법으로 이 때는 기아 문제가 발생한다.
2 ) 로빈 스케줄링을 결합하여 Time slice를 하는 방법이다. 주로 포그라운드 큐에 cpu의 80%를 백그라운드에 20%의 작업 시간을 부과한다.
5개의 큐를 가진 다단계 큐 스케줄링은 다음과 같은 우선순위를 갖는다.

[다단계 피드백 큐 스케줄링]
다단계 큐 스케줄링 알고리즘에서는 일반적으로 프로세스들은 하나의 큐에 할당되며 할당된 큐는 다른 큐들로 이동이 불가능하다. 이러한 방식은 스케줄링의 오버헤드가 장점이 있으나 융통성이 적다.
다단계 피드백 큐 스케줄링에서는 프로세스가 큐들 사이를 이동하는 것을 허용한다.
프로세스는 cpu버스트에 따라 구분되는데 만약 어떤 프로세스가 CPU를 너무 많이 사용하면, 낮은 우선순위의 큐로 이동된다. 마찬가지로 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스들은 위로 이동할 수 있다. 이런 상태로 기아 문제를 예방할 수 있다.